생성형 AI 모델의 성능을 강화하는 그래프 데이터베이스 Neo4j
효율적인 생성형 AI 운영을 위해 고객들은 별도로 Vector Database를 구매하곤 합니다. 이러한 Vector DB를 대체 가능한 것이 Neo4j의 솔루션입니다. Neo4j의 그래프 데이터베이스 플랫폼은 Microosft Azure, Google Cloud, AWS 등 클라우드 기반의 생성형 AI와 결합하여 사용되기도 합니다. 이를 통해 비즈니스가 생성형 AI 모델의 성능을 강화하고 패턴 식별을 개선하고 사용자가 자연어로 데이터를 탐색하도록 지원합니다.
지식 그래프를 구축하기 위해 생성형 AI를 사용해야 하는 이유는 무엇입니까?
기업은 방대한 양의 데이터에서 가치를 추출하는 데 어려움을 겪고 있습니다. 정형 데이터는 잘 정의된 API를 통해 다양한 형식으로 제공됩니다. 문서, 엔지니어링 도면, 사례 시트, 재무 보고서에 포함된 비정형 데이터는 포괄적인 지식 관리 시스템에 통합하기가 더 어려울 수 있습니다.
Neo4j를 사용하면 구조화된 소스와 구조화되지 않은 소스에서 지식 그래프를 구축할 수 있습니다. 해당 데이터를 그래프로 모델링하면 해당 데이터에서 다른 방법으로는 얻을 수 없는 통찰력을 얻을 수 있습니다. 그래프 데이터는 처리하기에 거대하고 지저분할 수 있습니다. Google Cloud의 생성적 AI를 사용하면 Neo4j에서 지식 그래프를 쉽게 구축한 다음 자연어를 사용하여 상호작용할 수 있습니다.
아래 아키텍처 다이어그램은 Google Cloud와 Neo4j가 협력하여 지식 그래프를 구축하고 상호 작용하는 방법을 보여줍니다.
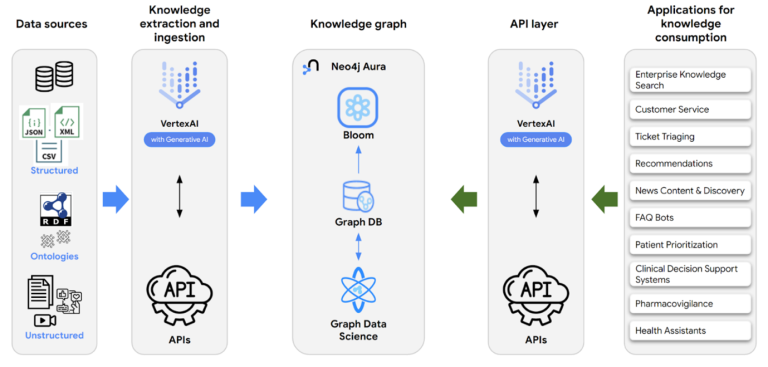
- 지식 추출– 다이어그램 왼쪽의 파란색 화살표는 정형 및 비정형 소스에서 Vertex AI로 흐르는 데이터를 보여줍니다. 생성형 AI는 해당 데이터에서 엔터티와 관계를 추출한 다음 Neo4j 데이터베이스에 대해 실행되는 Neo4j Cypher 쿼리로 변환되어 지식 그래프를 채우는 데 사용됩니다. 이 작업은 전통적으로 수작업으로 수행되었습니다. 생성형 AI를 사용하면 데이터 정리 및 통합의 수동 작업이 상당 부분 제거됩니다.
- 지식 소비– 다이어그램 오른쪽의 녹색 화살표는 지식 그래프를 사용하는 애플리케이션을 표시합니다. 사용자에게 자연어 인터페이스를 제공합니다. Vertex AI의 생성형 AI는 해당 자연어를 Neo4j 데이터베이스에 대해 실행되는 Neo4j Cypher로 변환합니다. 이를 통해 비기술적인 사용자도 생성형 AI 없이 가능했던 것보다 데이터베이스와 더 긴밀하게 상호 작용할 수 있습니다.
- 의료– 환자 결과 개선을 위해 다발성 경화증에 대한 환자 여정 모델링
- 제조– 생성 AI를 사용하여 도메인 전반에 걸쳐 BOM을 수집합니다. 이는 이전 수동 접근 방식으로는 처리할 수 없었던 작업입니다.
- 석유 및 가스– 데이터 과학 배경이 없는 사용자가 상호 작용할 수 있는 기술 문서에서 추출한 지식 기반을 구축합니다. 이를 통해 직원들은 더욱 신속하게 스스로 교육을 받고 비즈니스에 대한 질문에 답할 수 있습니다.
데이터 세트 및 아키텍처
이 예시에서는 Vertex AI의 생성형 AI 기능을 사용하여 SEC(증권거래위원회)의 문서를 파싱하겠습니다. 1억 달러 이상을 관리하는 자산 관리자는 분기에 한 번 Foam 13을 제출해야 합니다. Foam 13에는 보유 자산이 설명되어 있습니다.
우리는 서로 다른 자산 관리자가 서로 공유하는 보유 자산을 보여주는 해당 엔터티로부터 지식 그래프를 구축할 것입니다.
이를 수행하는 아키텍처는 위에서 본 아키텍처의 특정 버전입니다.
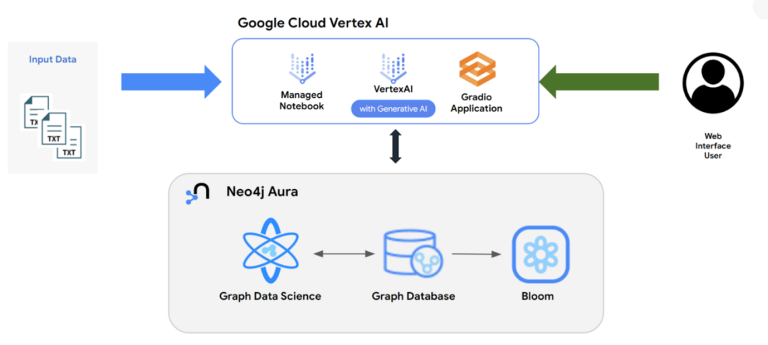
지식 추출
Neo4j는 유연한 스키마 데이터베이스로, 새로운 데이터와 관련 스키마를 가져와서 기존 스키마에 연결하거나 사용 사례에 따라 기존 스키마를 반복적으로 수정할 수 있습니다.
다음은 데이터 세트를 나타내는 스키마입니다.

비정형 데이터를 Neo4j로 전송하려면 먼저 엔터티와의 관계를 추출해야 합니다. 이것이 바로 Google의 PaLM 2 와 같은 생성형 AI 기반 모델이 도움이 될 수 있는 부분입니다. PaLM 2 모델은 프롬프트 엔지니어링을 사용하여 우리가 선택한 형식으로 관련 데이터를 추출할 수 있습니다. 챗봇 사례에서는 PaLM 2의 ” text-bison” 모델을 사용하여 여러 프롬프트를 연결할 수 있으며, 각각의 프롬프트는 입력 텍스트에서 특정 엔터티와의 관계를 추출합니다. 프롬프트를 연결하면 토큰 제한 오류를 방지하는 데 도움이 될 수 있습니다.
아래 프롬프트는 Form13 문서에서 회사 및 보유 정보를 JSON 형식으로 추출하는 데 사용할 수 있습니다.
mgr_info_tpl = “””From the text below, extract the following as json. Do not miss any of this information.
* The tags mentioned below may or may not be namespaced. So extract accordingly. Eg: <ns1:tag> is equal to <tag>
* “name” – The name from the <name> tag under <filingManager> tag
* “street1” – The manager’s street1 address from the <com:street1> tag under <address> tag
* “street2” – The manager’s street2 address from the <com:street2> tag under <address> tag
* “city” – The manager’s city address from the <com:city> tag under <address> tag
* “stateOrCounty” – The manager’s stateOrCounty address from the <com:stateOrCountry> tag under <address> tag
* “zipCode” – The manager’s zipCode from the <com:zipCode> tag under <address> tag
* “reportCalendarOrQuarter” – The reportCalendarOrQuarter from the <reportCalendarOrQuarter> tag under <address> tag
* Just return me the JSON enclosed by 3 backticks. No other text in the response
Text:
$ctext
“””
text-bison 모델의 출력은 다음과 같습니다.
{‘name’: ‘TIGER MANAGEMENT L.L.C.’,
‘street1’: ‘101 PARK AVENUE’,
‘street2’: ”,
‘city’: ‘NEW YORK’,
‘stateOrCounty’: ‘NY’,
‘zipCode’: ‘10178’,
‘reportCalendarOrQuarter’: ’03-31-2023′}
Text-bison 모델은 텍스트를 이해하고 우리가 원하는 출력 형식으로 정보를 추출할 수 있었습니다. 이것이 Neo4j 브라우저에서 어떻게 보이는지 살펴보겠습니다.
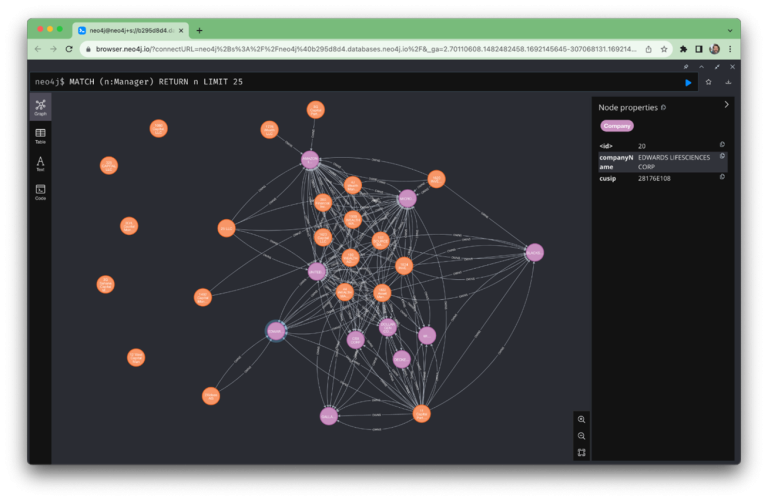
위의 스크린샷은 Neo4j 그래프 데이터베이스에서 저장된 우리가 구축한 지식 그래프를 보여줍니다.
우리는 이제 Vertex AI의 생성형 AI를 사용하여 반정형 데이터에서 엔터티와 관계를 추출했습니다. 이러한 정보를 Vertex AI에서 생성한 Cypher 쿼리를 사용하여 Neo4j에 작성했습니다. 이러한 단계는 이전에는 수동으로 이루어져야 했습니다. 생성형 AI는 이러한 작업을 자동화하여 시간과 노력을 절약하는 데 도움을 줍니다.
지식 소비
이제 지식 그래프를 구축했으므로 여기에서 데이터를 사용할 수 있습니다. Cypher는 Neo4j의 쿼리 언어입니다. 챗봇을 구축하려면 입력된 자연어(영어)를 Cypher로 변환해야 합니다. PaLM 2와 같은 모델이 이를 수행할 수 있습니다. 기본 모델은 좋은 결과를 생성하지만 더 나은 정확도를 달성하기 위해 두 가지 추가 기술을 사용할 수 있습니다.
- 프롬프트 엔지니어링– 원하는 출력을 달성하기 위해 모델 입력에 몇 가지 샘플을 제공합니다. 또한 특정 Cypher 출력을 달성하는 방법을 모델에 가르치기 위해 일련의 사고 유도를 시도할 수도 있습니다 .
- 어댑터 튜닝(효율적인 매개 변수 조정)– 샘플 데이터를 사용하여 모델을 어댑터 튜닝할 수도 있습니다. 이런 방식으로 생성된 가중치는 테넌트 내에 유지됩니다.
이 경우 데이터 흐름은 다음과 같습니다.
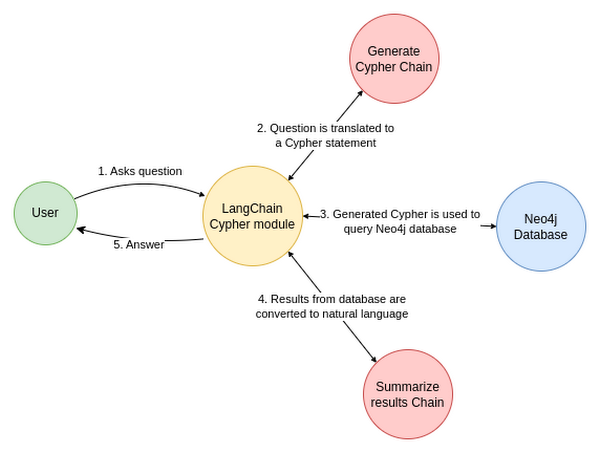
튜닝된 모델을 사용하면 간단한 프롬프트를 통해 다음과 같이 text-bison을 Cypher 전문가로 변환할 수 있습니다.
#prompt/template
CYPHER_GENERATION_TEMPLATE = “””You are an expert Neo4j Cypher translator who understands the question in english and convert to Cypher strictly based on the Neo4j Schema provided and following the instructions below:
- Generate Cypher query compatible ONLY for Neo4j Version 5
- Do not use EXISTS, SIZE keywords in the Cypher. Use alias when using the WITH keyword
- Please do not use the same variable names for different nodes and relationships in the query.
- Use only Nodes and relationships mentioned in the schema
- Always enclose the Cypher output inside 3 backticks
- Always do a case-insensitive and fuzzy search for any properties related search. Eg: to search for a Company name use `toLower(c.name) contains ‘neo4j’`
- Candidate node is synonymous to Manager
- Always use aliases to refer the node in the query
- ‘Answer’ is NOT a Cypher keyword. Answers should never be used in a query.
- Please generate only one Cypher query per question.
- Cypher is NOT SQL. So, do not mix and match the syntaxes.
- Every Cypher query always starts with a MATCH keyword.
그러면 Vertex AI의 생성형 AI는 “FAANG 주식을 소유한 관리자는 누구입니까?”와 같은 질문에 응답할 수 있습니다. Cypher에서는 이렇게 합니다:
MATCH (m:Manager) -[o:OWNS]-> (c:Company) WHERE toLower(c.companyName) IN [“facebook”, “apple”, “amazon”, “netflix”, “google”] RETURN m.managerName AS manager
정말 놀랍습니다. Vertex AI는 FAANG의 의미를 이해하고 이를 회사 이름에 매핑한 다음 이를 기반으로 Cypher 쿼리를 생성했습니다. 최종 답변은 “Beacon Wealthcare LLC와 Pinnacle Holdings, LLC가 FAANG 주식을 소유하고 있습니다.”입니다.
Gradio는 이 모든 것을 마무리하기 위해 멋진 챗봇 위젯도 제공합니다.
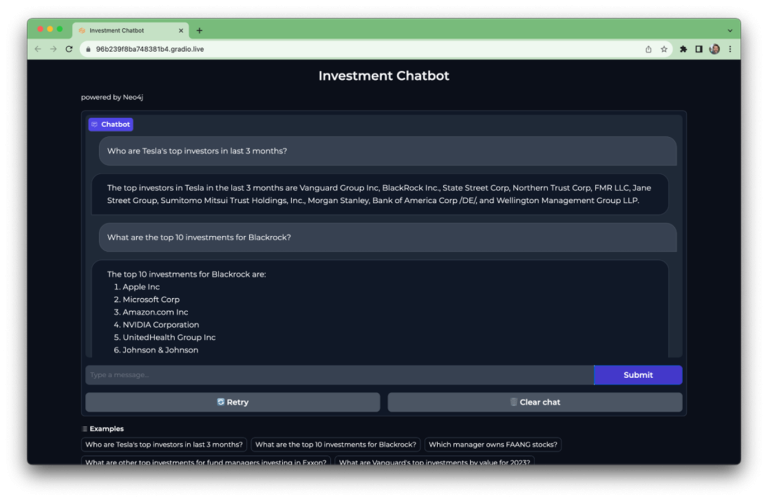
이 챗봇에는 시작하는 데 도움이 되는 몇 가지 예시 질문이 포함되어 있습니다.
요약
이 블로그 게시물에서는 두 부분으로 구성된 데이터 흐름을 살펴보았습니다.
- 지식 추출– 반정형 데이터에서 엔터티와 관계를 가져와서 지식 그래프를 작성합니다.
- 지식 소비– 사용자가 자연어를 사용하여 해당 지식 그래프에 대해 질문할 수 있도록 합니다.
각각의 경우에 이를 가능하게 한 것은 Google Cloud Vertex AI와 Neo4j의 생성형 AI 기능의 고유한 조합이었습니다. 이 접근 방식은 이전에는 매우 수동적이었던 프로세스를 자동화하고 단순화합니다. 이를 통해 이전에는 가능하지 않았던 문제 클래스에 지식 그래프 접근 방식을 적용할 수 있게 되었습니다.
Neo4j와 Cloocus
그래프 데이터베이스 및 분석의 선두주자인 Neo4j는 기업이 수십억 개의 연결된 데이터에서 숨겨진 관계와 패턴을 깊고 쉽고 빠르게 찾을 수 있도록 도와줍니다. 고객은 연결된 데이터의 구조를 활용하여 데이터가 증가함에 따라 사기 탐지, 고객 360, 지식 그래프, 공급망, 개인화, IoT, 네트워크 관리 등 가장 시급한 비즈니스 문제를 해결하는 새로운 방법을 제시합니다. Neo4j의 전체 그래프 스택은 엔터프라이즈급 보안 제어, 확장 가능한 아키텍처 및 ACID 준수를 통해 강력한 기본 그래프 스토리지, 데이터 과학, 고급 분석 및 시각화를 제공합니다. Neo4j의 데이터 리더 커뮤니티는 수백 개의 Fortune 500대 기업, 정부 기관 및 NGO에 걸쳐 250,000명 이상의 개발자, 데이터 과학자 및 설계자로 구성된 활발한 오픈 소스 커뮤니티로 구성됩니다.
클루커스는 Neo4j와의 파트너십을 통해 고객에게 생성형 AI를 활용하여 더 나은 혁신을 추구하는 고객을 지원합니다. 클루커스는 숙련된 Data & AI 전문가 그룹를 통하여 최근 각광받고 있는 생성형 AI 기술을 빠르게 습득하고 있습니다. 생성형 AI 도입과 관련하여 전문가의 상담이 필요하시다면 아래 버튼을 통해 전문가 컨설팅을 신청하세요!
필요하다면 클루커스에 문의하세요!